Texture MTF is a method to measure the sharpness of a digital camera and lens by capturing the image of a target of known characteristics. It purports to better evaluate the perception of fine details in low contrast areas of the image – what is referred to as ‘texture’ – in the presence of noise reduction, sharpening or other non-linear processing performed by the camera before writing data to file.

The Modulation Transfer Function (MTF) of an imaging system represents its spatial frequency response, from which many metrics related to perceived sharpness are derived: MTF50, SQF, SQRI, CMT Acutance etc. In these pages we have used to good effect the slanted edge method to obtain accurate estimates of a system’s MTF curves in the past.[1]
In this article we will explore proposed methods to determine Texture MTF and/or estimate the Optical Transfer Function of the imaging system under test from a reference power-law Power Spectrum target. All three rely on variations of the ratio of captured to reference image in the frequency domain: straight Fourier Transforms; Power Spectral Density; and Cross Power Density. In so doing we will develop some intuitions about their strengths and weaknesses. Continue reading Introduction to Texture MTF

 as described there.
as described there.


 ) of about 1000 watts per square meter. As discussed
) of about 1000 watts per square meter. As discussed  ) – or as a certain number of photons per second (
) – or as a certain number of photons per second ( ) over an area of interest (
) over an area of interest ( ).
).
 per unit area can we expect on the camera’s image plane (irradiance
per unit area can we expect on the camera’s image plane (irradiance  )?
)?


 color space, obtained by multiplying wavelength-by-wavelength its SPD (the blue curve below) by the Color Matching Functions of a Standard Observer (
color space, obtained by multiplying wavelength-by-wavelength its SPD (the blue curve below) by the Color Matching Functions of a Standard Observer ( )
)
 value to normalize it to 1.
value to normalize it to 1. = [0.9593 1.0000 0.8833]
= [0.9593 1.0000 0.8833]  ,
,  ,
,  for short.
for short. triplet representing a point within it. The system is bounded in the raw data by the extent of the Analog to Digital Converter, with all three channels spanning the same range, from Black Level with no light to clipping with maximum recordable light. Therefore it can be thought to represent a space in the form of a cube – or better, a parallelepiped – with the origin at [0,0,0] and the opposite vertex at the clipping value in Data Numbers, expressed as [1,1,1] if we normalize all data by it.
triplet representing a point within it. The system is bounded in the raw data by the extent of the Analog to Digital Converter, with all three channels spanning the same range, from Black Level with no light to clipping with maximum recordable light. Therefore it can be thought to represent a space in the form of a cube – or better, a parallelepiped – with the origin at [0,0,0] and the opposite vertex at the clipping value in Data Numbers, expressed as [1,1,1] if we normalize all data by it.
 color space designed for viewing. Such spaces have names like
color space designed for viewing. Such spaces have names like  ,
,  or
or  . The output space can also be shown in 3D as a parallelepiped with the origin at [0,0,0] with no light and the opposite vertex at [1,1,1] with maximum displayable light.
. The output space can also be shown in 3D as a parallelepiped with the origin at [0,0,0] with no light and the opposite vertex at [1,1,1] with maximum displayable light.  ,
,  ,
,  displayed in Figure 1 are an exact linear transform of Stockman & Sharpe (2000) 2 deg Cone Fundamentals
displayed in Figure 1 are an exact linear transform of Stockman & Sharpe (2000) 2 deg Cone Fundamentals  ,
,  ,
,  displayed in Figure 2
displayed in Figure 2![\begin{equation*} \left[ \begin{array}{c} \bar{x}} \\ \bar{y} \\ \bar{z} \end{array} \right] = M_{lx} * \left[ \begin{array} {c}\bar{\rho} \\ \bar{\gamma} \\ \bar{\beta} \end{array} \right] \end{equation*}](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-641037cf449c1fce6e76d66b53f1d297_l3.png?resize=161%2C64&ssl=1 "Rendered by QuickLaTeX.com")
 a 3×3 matrix and
a 3×3 matrix and  matrix multiplication. Et voilà:
matrix multiplication. Et voilà:
 values recorded in the raw data in the center of the image plane in units of Data Numbers per pixel – by a digital camera and lens as a function of absolute spectral radiance
values recorded in the raw data in the center of the image plane in units of Data Numbers per pixel – by a digital camera and lens as a function of absolute spectral radiance  at the lens – can be estimated as follows:
at the lens – can be estimated as follows:
 indicating absolute-referred units and
indicating absolute-referred units and  the three system Spectral Sensitivity Functions. In this series of articles
the three system Spectral Sensitivity Functions. In this series of articles  is wavelength by wavelength multiplication (what happens to the spectrum of light as it progresses through the imaging system) and the integral just means the area under each of the three resulting curves (integration is what the pixels do during exposure). Together they represent an inner or dot product. All variables in front of the integral were previously described and can be considered constant for a given photographic setup.
is wavelength by wavelength multiplication (what happens to the spectrum of light as it progresses through the imaging system) and the integral just means the area under each of the three resulting curves (integration is what the pixels do during exposure). Together they represent an inner or dot product. All variables in front of the integral were previously described and can be considered constant for a given photographic setup. 




 = 3.65 microns. That’s about the size of the estimated effective square pixel aperture of the Nikon Z7 camera that we are using in these tests.
= 3.65 microns. That’s about the size of the estimated effective square pixel aperture of the Nikon Z7 camera that we are using in these tests.




 , the scalar quantity to minimize, function of ideal image
, the scalar quantity to minimize, function of ideal image 
 , linear captured image intensity laid out in
, linear captured image intensity laid out in  rows and
rows and  columns, corrupted by Poisson noise and blurring by the
columns, corrupted by Poisson noise and blurring by the 
 , the known two-dimensional Point Spread Function that should be deconvolved out of
, the known two-dimensional Point Spread Function that should be deconvolved out of 
 element-wise product
element-wise product , element-wise natural logarithm
, element-wise natural logarithm and
and  , from zero to
, from zero to  that we are after?
that we are after?






 twice in sequence.
twice in sequence. space to a Fast Fourier Transform routine and, presto, it produces MxN numbers representing the amplitude of the PSF on the
space to a Fast Fourier Transform routine and, presto, it produces MxN numbers representing the amplitude of the PSF on the  sensing plane. Figure 1a shows a simple case where pupil function
sensing plane. Figure 1a shows a simple case where pupil function 
 arrives at the front of the lens. It goes through the lens being partly blocked and distorted by it as it arrives at its virtual back end, the Exit Pupil, we’ll call this blocking/distorting function
arrives at the front of the lens. It goes through the lens being partly blocked and distorted by it as it arrives at its virtual back end, the Exit Pupil, we’ll call this blocking/distorting function  . Other than in very simple cases, the Exit Pupil does not necessarily coincide with a specific physical element or Principal surface.
. Other than in very simple cases, the Exit Pupil does not necessarily coincide with a specific physical element or Principal surface. as shown below (not to scale, the product of the two arrays is element-by-element):
as shown below (not to scale, the product of the two arrays is element-by-element):
 connection space – and where to obtain the 3×3 linear matrix to then convert it to a standard output color space like sRGB – we can take a closer look at the matrices and apply them to a real world capture chosen for its wide range of chromaticities.
connection space – and where to obtain the 3×3 linear matrix to then convert it to a standard output color space like sRGB – we can take a closer look at the matrices and apply them to a real world capture chosen for its wide range of chromaticities.
![\[ Raw Data \rightarrow XYZ_{D50} \rightarrow RGB_{standard} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-062c1798a46be7f6f42a79b450d40bde_l3.png?resize=298%2C15&ssl=1 "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{c} X_{D50} \\ Y_{D50} \\ Z_{D50} \end{array} \right] = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \left[ \begin{array}{c} r \\ g \\ b \end{array} \right] \end{equation*}](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-b9f4277814179e1fbcf64e1a69a53818_l3.png?resize=273%2C64&ssl=1 "Rendered by QuickLaTeX.com")
 coefficients of this matrix
coefficients of this matrix  ,
,  or
or  ) in the fovea produces the same stimulus to the brain regardless of its wavelength
) in the fovea produces the same stimulus to the brain regardless of its wavelength









 ), that is the individual MTFs of the perfect lens PSF, the perfect square pixel and the delta grid;
), that is the individual MTFs of the perfect lens PSF, the perfect square pixel and the delta grid;  represents two dimensional convolution.
represents two dimensional convolution.

 here indicating normalization to one at the origin). I used Matlab to generate the examples below but you can easily do the same with a spreadsheet.
here indicating normalization to one at the origin). I used Matlab to generate the examples below but you can easily do the same with a spreadsheet. ![\[ MTF_{2D} = \left|\widehat{ PSF_{lens} }\cdot \widehat{PIX_{ap} }\right|_{pu}\ast\ast\: \delta\widehat{\delta_{pitch}} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-3409f065a49bb47fd4618ed595be72fc_l3.png?resize=320%2C37&ssl=1 "Rendered by QuickLaTeX.com")


![\[ DR = \frac{Maximum Signal}{Minimum Signal} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-f89166dae7cfbfc1a37b1ef0f536dd7e_l3.png?resize=194%2C41&ssl=1 "Rendered by QuickLaTeX.com")
![\[ DR = log_2(\frac{Maximum Acceptable Signal}{Minimum Acceptable Signal}) \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-c691db4feaf1e0b8c2cf50cb84b5b7bf_l3.png?resize=321%2C41&ssl=1 "Rendered by QuickLaTeX.com")



 the signal in photoelectrons and
the signal in photoelectrons and  the
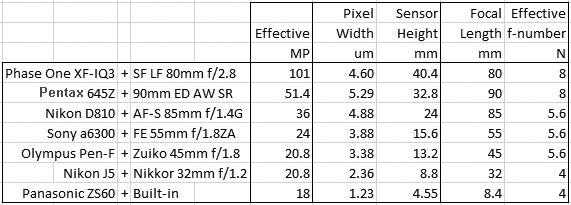
the  independently of format. Ignoring noise, lenses and aspect ratio for a moment and assuming the same camera gain and number of pixels, they will produce identical raw files.
independently of format. Ignoring noise, lenses and aspect ratio for a moment and assuming the same camera gain and number of pixels, they will produce identical raw files. 

 is called Spectral Exitance, with the symbol
is called Spectral Exitance, with the symbol  when referred to units of energy. The energy of one photon at a given wavelength is
when referred to units of energy. The energy of one photon at a given wavelength is
 the wavelength of light in meters and
the wavelength of light in meters and  and
and  Planck’s constant and the speed of light in the chosen medium respectively. Since Watts are joules per second the units of (1) are therefore
Planck’s constant and the speed of light in the chosen medium respectively. Since Watts are joules per second the units of (1) are therefore  . Writing it more formally:
. Writing it more formally:
 .
. 