We understand from the previous article that the process of digitizing an optical image with a photographic sensor can be thought of as two subsequent operations:
- filtering (convolution) of the optical image on the sensing plane by the pixel’s finite effective active area (aka pixel aperture);
- point sampling the convolved image at a given fixed rate and position, often corresponding to the center of each pixel.
Both affect resolution in different ways: the former can be thought of as modifying continuously the analog optical image, as seen below right; the latter as possibly introducing interference (aliasing) into the result.

In this page I will explore how the act of digitizing that image – the process of sampling – fundamentally alters what we can resolve. In the next one we will discuss the impact on resolution of pixel-shift modes available in current mirrorless cameras. Continue reading The Effect of Sampling on Image Resolution




 as earlier described.
as earlier described.


 ) of about 1000 watts per square meter. As discussed
) of about 1000 watts per square meter. As discussed  ) – or equivalently as a certain number of photons per second (
) – or equivalently as a certain number of photons per second ( ) over an area of interest (
) over an area of interest ( )
)
 per unit area can we expect on the camera’s image plane (irradiance
per unit area can we expect on the camera’s image plane (irradiance  )?
)?


 color space, obtained by multiplying wavelength-by-wavelength its SPD (the blue curve below) by the response of the retina of a typical viewer, otherwise known as the CIE Color Matching Functions of a Standard Observer (
color space, obtained by multiplying wavelength-by-wavelength its SPD (the blue curve below) by the response of the retina of a typical viewer, otherwise known as the CIE Color Matching Functions of a Standard Observer ( in the plot)
in the plot)
 value to normalize it to 1.
value to normalize it to 1. = [0.9593 1.0000 0.8833]
= [0.9593 1.0000 0.8833]
 to a standard output
to a standard output  color space designed for viewing. Such spaces have names like
color space designed for viewing. Such spaces have names like  ,
,  or
or  . The output space can also be shown in 3D as a parallelepiped with the origin at [0,0,0] with no light and the opposite vertex at [1,1,1] with maximum displayable light.
. The output space can also be shown in 3D as a parallelepiped with the origin at [0,0,0] with no light and the opposite vertex at [1,1,1] with maximum displayable light.  ,
,  ,
,  displayed in Figure 1 are an exact linear transform of Stockman & Sharpe (2000) 2 deg Cone Fundamentals
displayed in Figure 1 are an exact linear transform of Stockman & Sharpe (2000) 2 deg Cone Fundamentals  ,
,  ,
,  displayed in Figure 2
displayed in Figure 2![\begin{equation*} \left[ \begin{array}{c} \bar{x}} \\ \bar{y} \\ \bar{z} \end{array} \right] = M_{lx} * \left[ \begin{array} {c}\bar{\rho} \\ \bar{\gamma} \\ \bar{\beta} \end{array} \right] \end{equation*}](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-113c1eb0539b73b34a046035e33979ea_l3.png?resize=161%2C64&ssl=1 "Rendered by QuickLaTeX.com")
 a 3×3 matrix and
a 3×3 matrix and  matrix multiplication. Et voilà:
matrix multiplication. Et voilà:
 values recorded in the raw data in the center of the image plane in units of Data Numbers per pixel – by a digital camera and lens as a function of absolute spectral radiance
values recorded in the raw data in the center of the image plane in units of Data Numbers per pixel – by a digital camera and lens as a function of absolute spectral radiance  at the lens – can be estimated as follows:
at the lens – can be estimated as follows:
 indicating absolute-referred units and
indicating absolute-referred units and  the three system Spectral Sensitivity Functions. In this series of articles
the three system Spectral Sensitivity Functions. In this series of articles  is wavelength by wavelength multiplication (what happens to the spectrum of light as it progresses through the imaging system) and the integral just means the area under each of the three resulting curves (integration is what the pixels do during exposure). Together they represent an inner or dot product. All variables in front of the integral were previously described and can be considered constant for a given photographic setup.
is wavelength by wavelength multiplication (what happens to the spectrum of light as it progresses through the imaging system) and the integral just means the area under each of the three resulting curves (integration is what the pixels do during exposure). Together they represent an inner or dot product. All variables in front of the integral were previously described and can be considered constant for a given photographic setup. 




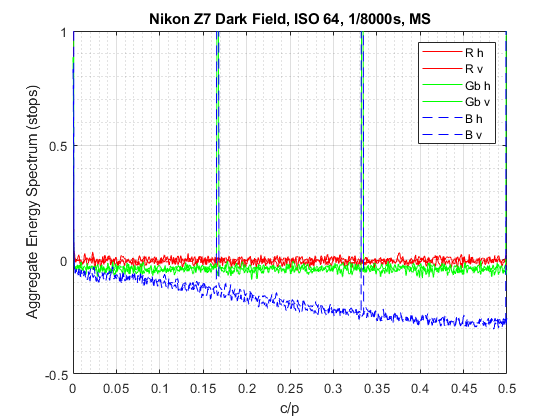
 = 3.65 microns. That’s about the size of the estimated effective square pixel aperture of the Nikon Z7 camera that we are using in these tests.
= 3.65 microns. That’s about the size of the estimated effective square pixel aperture of the Nikon Z7 camera that we are using in these tests.




 , the scalar quantity to minimize, function of ideal image
, the scalar quantity to minimize, function of ideal image 
 , linear captured image intensity laid out in
, linear captured image intensity laid out in  rows and
rows and  columns, corrupted by Poisson noise and blurred by the
columns, corrupted by Poisson noise and blurred by the 
 , the known two-dimensional Point Spread Function that should be deconvolved out of
, the known two-dimensional Point Spread Function that should be deconvolved out of 
 element-wise product
element-wise product , element-wise natural logarithm
, element-wise natural logarithm and
and  , from zero to
, from zero to  that we are after?
that we are after?
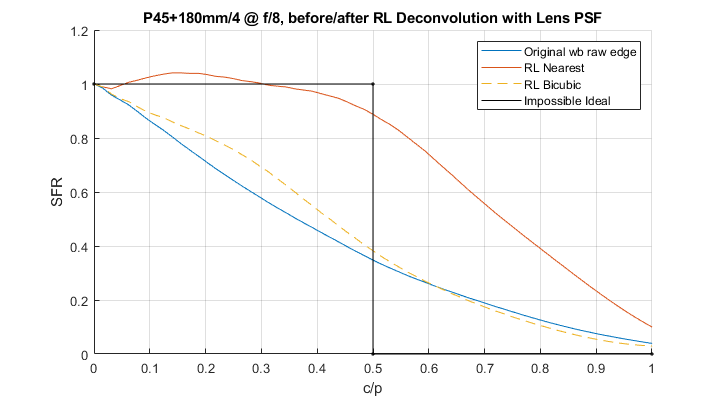






 twice in sequence.
twice in sequence. space to a Fast Fourier Transform routine and, presto, it produces MxN numbers representing the amplitude of the PSF on the
space to a Fast Fourier Transform routine and, presto, it produces MxN numbers representing the amplitude of the PSF on the  sensing plane. Figure 1a shows a simple case where pupil function
sensing plane. Figure 1a shows a simple case where pupil function 
 arrives at the front of the lens. It goes through the lens being partly blocked and distorted by it as it arrives at its virtual back end, the Exit Pupil, we’ll call this blocking/distorting function
arrives at the front of the lens. It goes through the lens being partly blocked and distorted by it as it arrives at its virtual back end, the Exit Pupil, we’ll call this blocking/distorting function  . Other than in very simple cases, the Exit Pupil does not necessarily coincide with a specific physical element or Principal surface.
. Other than in very simple cases, the Exit Pupil does not necessarily coincide with a specific physical element or Principal surface. as shown below (not to scale, the product of the two arrays is element-by-element):
as shown below (not to scale, the product of the two arrays is element-by-element):
 connection space – and where to obtain the 3×3 linear matrix to then convert it to a standard output color space like sRGB – we can take a closer look at the matrices and apply them to a real world capture chosen for its wide range of chromaticities.
connection space – and where to obtain the 3×3 linear matrix to then convert it to a standard output color space like sRGB – we can take a closer look at the matrices and apply them to a real world capture chosen for its wide range of chromaticities.
![\[ Raw Data \rightarrow XYZ_{D50} \rightarrow RGB_{standard} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-164bf80016fc459bad893b6930883830_l3.png?resize=298%2C15&ssl=1 "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{c} X_{D50} \\ Y_{D50} \\ Z_{D50} \end{array} \right] = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \left[ \begin{array}{c} r \\ g \\ b \end{array} \right] \end{equation*}](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-f4f3535c40e6f7d83ee139eaf9633956_l3.png?resize=273%2C64&ssl=1 "Rendered by QuickLaTeX.com")
 coefficients of this matrix
coefficients of this matrix  ,
,  or
or  ) in the fovea produces the same stimulus to the brain regardless of its wavelength
) in the fovea produces the same stimulus to the brain regardless of its wavelength









 ), that is the individual MTFs of the perfect lens PSF, the perfect square pixel and the delta grid;
), that is the individual MTFs of the perfect lens PSF, the perfect square pixel and the delta grid;  represents two dimensional convolution.
represents two dimensional convolution.

 here indicating normalization to one at the origin). I used Matlab to generate the examples below but you can easily do the same with a spreadsheet.
here indicating normalization to one at the origin). I used Matlab to generate the examples below but you can easily do the same with a spreadsheet. ![\[ MTF_{2D} = \left|\widehat{ PSF_{lens} }\cdot \widehat{PIX_{ap} }\right|_{pu}\ast\ast\: \delta\widehat{\delta_{pitch}} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-8dac44a5e303eacd5a262b2c42296a14_l3.png?resize=320%2C37&ssl=1 "Rendered by QuickLaTeX.com")

 ) that reflects the mix of spectral information captured in the raw data, divorced from downstream color science; and
) that reflects the mix of spectral information captured in the raw data, divorced from downstream color science; and ) that reflects the luminance channel of the image as neutrally displayed, hence may be more perceptually relevant.
) that reflects the luminance channel of the image as neutrally displayed, hence may be more perceptually relevant.
![\[ DR = \frac{Maximum Signal}{Minimum Signal} \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-0ef4805cfe0248405c147608a20bbc30_l3.png?resize=194%2C40&ssl=1 "Rendered by QuickLaTeX.com")
![\[ DR = log_2(\frac{Maximum Acceptable Signal}{Minimum Acceptable Signal}) \]](https://i0.wp.com/www.strollswithmydog.com/wordpress/wp-content/ql-cache/quicklatex.com-90d22584b8704a2407dc7c112466d0a6_l3.png?resize=321%2C41&ssl=1 "Rendered by QuickLaTeX.com")



 the signal in photoelectrons and
the signal in photoelectrons and  the
the  independently of format. Ignoring noise, lenses and aspect ratio for a moment and assuming the same camera gain and number of pixels, they will produce identical raw files.
independently of format. Ignoring noise, lenses and aspect ratio for a moment and assuming the same camera gain and number of pixels, they will produce identical raw files. 


 is called Spectral Exitance, with the symbol
is called Spectral Exitance, with the symbol  when referred to units of energy. The energy of one photon at a given wavelength is
when referred to units of energy. The energy of one photon at a given wavelength is
 the wavelength of light in meters and
the wavelength of light in meters and  and
and  Planck’s constant and the speed of light in the chosen medium respectively. Since Watts are joules per second the units of (1) are therefore
Planck’s constant and the speed of light in the chosen medium respectively. Since Watts are joules per second the units of (1) are therefore  . Writing it more formally:
. Writing it more formally:
 ) – while in photography the same concepts are dealt with in photometric units like lumens (
) – while in photography the same concepts are dealt with in photometric units like lumens ( ).
). .
. 